
Musical Audio Generation#
Table of Contents#
Basics of Generative Modeling
Early Works
Examples
Goal of the Task#
Musical audio generation aims to create various musical content, from individual notes [EAC+19] to instrumental accompaniments/arrangements [NPA+24] and complete songs [ECT+24]. In the early days of audio generation research, methods often focused on producing audio directly in the time or time-frequency domain. Recent approaches, however, work with compressed representations, often using neural audio codecs.
The most widely used models today are autoregressive (Transformer) architectures and diffusion models. Autoregressive architectures are particularly effective for discrete codecs, while diffusion models are better suited for continuous representations.
Popular Datasets#
NSynth: NSynth is a dataset designed for musical audio generation, often regarded as the “MNIST” of audio. It contains 305,979 short, single-note audio samples from 1,006 instruments, each labeled with attributes such as pitch, velocity, and instrument family. This dataset is valuable for early experiments in audio synthesis and machine learning. NSynth Dataset
MusicNet: MusicNet is a collection of 330 freely-licensed classical music recordings, totaling over 34 hours of audio. It includes more than 1 million annotated labels indicating the precise timing, instrument, and position of each note in the compositions. This dataset is suitable for tasks involving complex musical structures and note prediction. MusicNet Dataset
MAESTRO: The MAESTRO (MIDI and Audio Edited for Synchronous TRacks and Organization) dataset features over 200 hours of virtuosic piano performances captured with aligned MIDI and audio recordings. It includes detailed metadata such as composer, title, and year of performance, making it particularly useful for training models in high-quality piano music generation. MAESTRO Dataset
MagnaTagATune: MagnaTagATune offers a large collection of music annotated with tags, useful for genre classification and multi-label tasks. It contains over 25,000 music clips, each 29 seconds long, with multiple annotations per clip, covering a wide range of genres and instruments. MagnaTagATune Dataset
How is the Task Evaluated?#
Evaluation of generation tasks is difficult. In other ML tasks, specific targets (e.g., labels, data points) are available in a given evaluation set, allowing precision estimation for a given model. In contrast, in audio generation, the goal is to sample from the distribution of the training set without directly reproducing any training data.
As a result, indirect, distribution-based evaluation metrics are commonly used rather than relying on one-to-one comparisons, as in autoencoders or classification tasks.
Frechet Audio Distance (FAD)#
Nowadays, the most commonly used metric in assessing the quality of generated audio is the Frechet Audio Distance (FAD) [KZRS19]. It compares the statistics of generated audio to those of real, high-quality reference samples (usually the test set) in the embedding space of a pre-trained model. The idea is to assess the “closeness” of the two distributions: one for the generated samples and one for real samples.
Origins and Motivation#
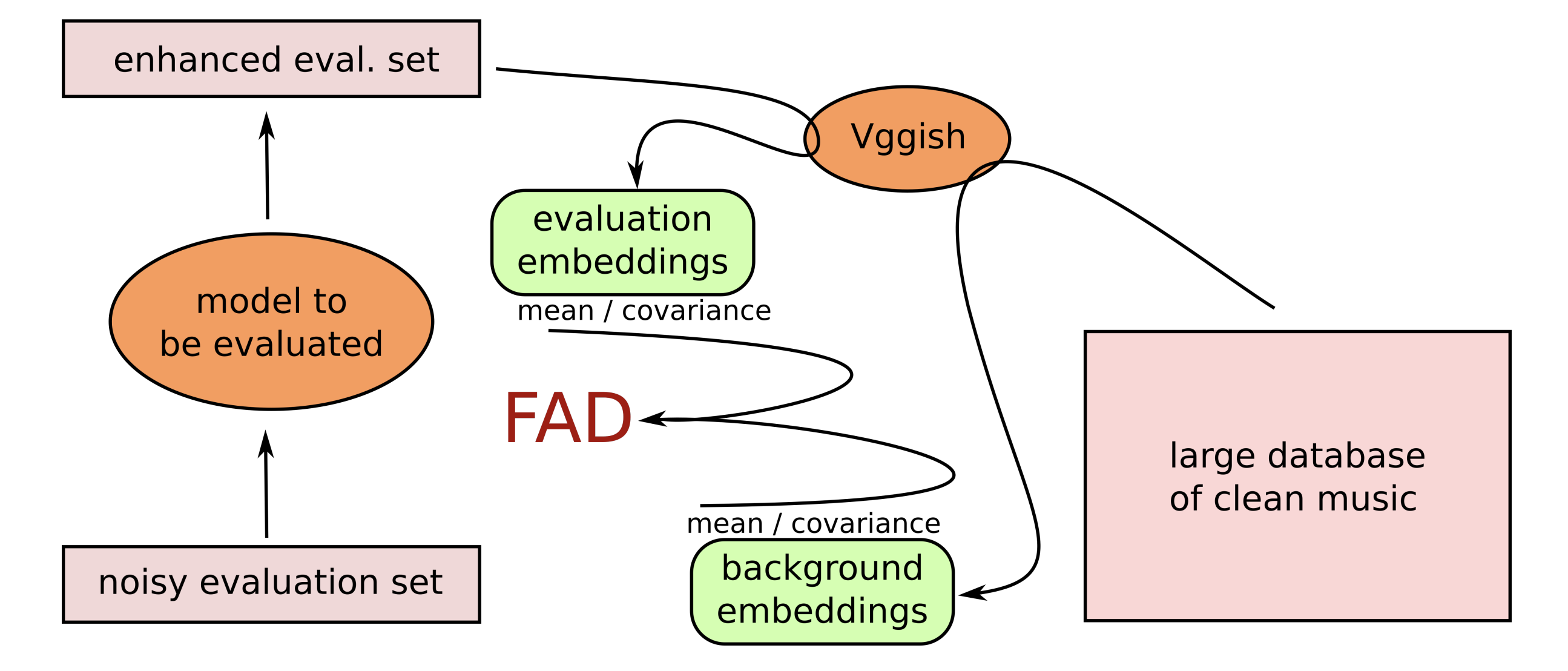
Figure 1: FAD computation overview for a music enhancement system as initially proposed (image source: [KZRS19]).
Fréchet Audio Distance was initially developed to evaluate music enhancement algorithms (see Figure 1). It filled a gap in objective audio quality evaluation, especially in generative tasks like music synthesis, audio inpainting, and speech generation. Before FAD, audio evaluations often relied on metrics like mean squared error (for reconstruction-based approaches) or subjective listening tests. While subjective tests remain essential for evaluating the perceptual quality of audio, FAD offers a more automated, quantifiable approach that aligns with perceptual quality.
Calculation of FAD#
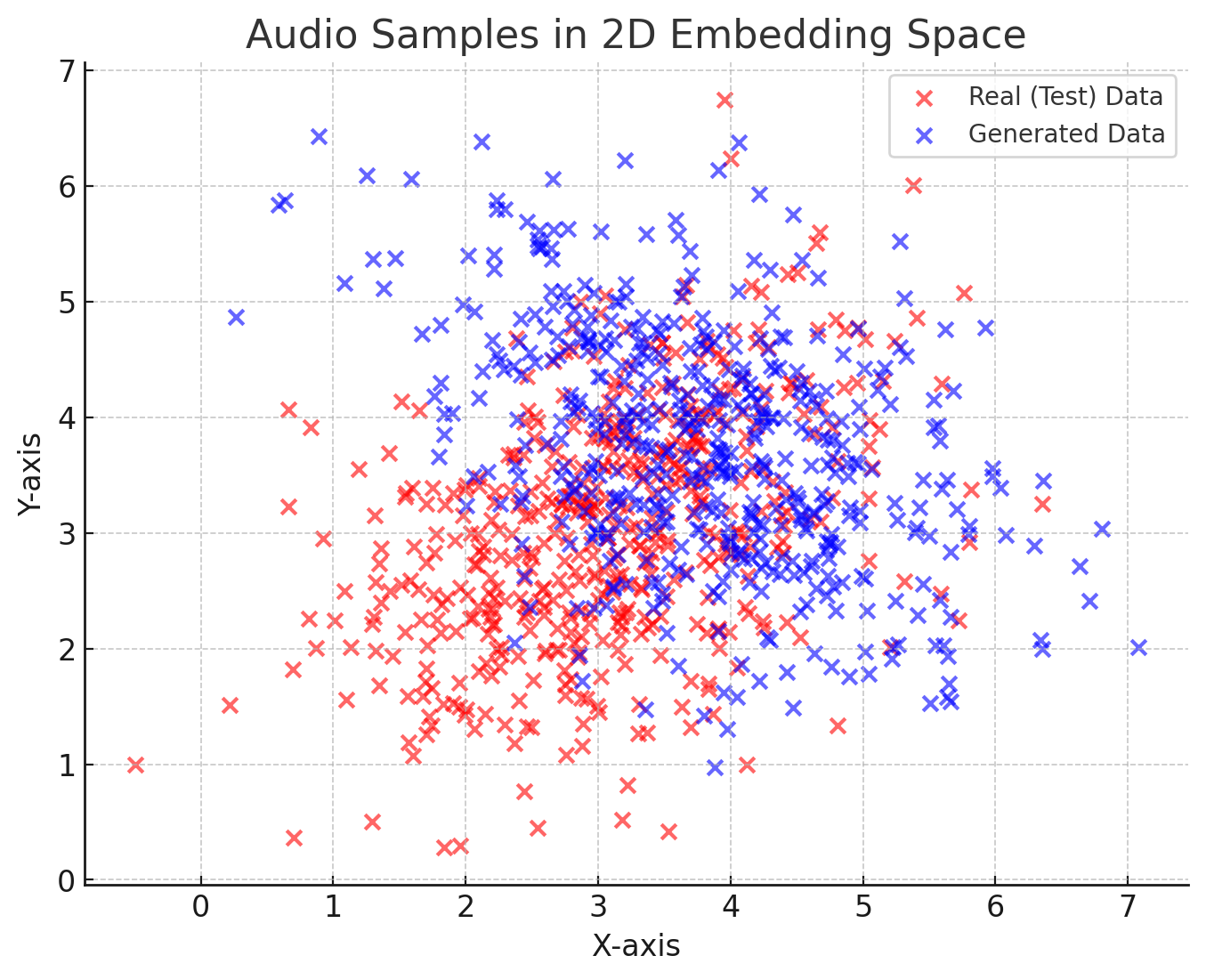
Figure 2: Example of audio samples projected in a 2d embedding space. The FAD in this example is \(1.47\).
The FAD metric works by embedding audio signals into a perceptual feature space using a pre-trained deep neural network model. Initially a VGGish model was proposed, but it has been shown that LAION CLAP embeddings [WCZ+23] or a specific PANN model [KCI+20] align better with perceived audio quality [GGBE24, TLL+24]. Once embedded, it treats these embeddings as multidimensional distributions and calculates the Fréchet Distance (also known as the Wasserstein-2 distance) between the two distributions.
Mathematically, it involves comparing the means and covariances of these distributions:
where \(\mu_r\) and \(\Sigma_r\) are the mean and covariance of the reference (real) distribution, and \(\mu_g\) and \(\Sigma_g\) are those of the generated distribution.
Applications of FAD#
FAD is widely used in research on generative audio models, including:
Music and Sound Generation: Evaluating GANs or VAEs that generate music, sound effects, or synthetic soundscapes.
Speech Synthesis: Benchmarking TTS (Text-to-Speech) systems to gauge how close generated speech is to natural human voices.
Audio Super-Resolution: Comparing high-resolution generated audio with real high-resolution samples.
Denoising and Enhancement: Assessing the quality of denoised or enhanced audio by comparing it to clean reference audio.
Since its introduction, FAD has become a standard metric for evaluating the realism and quality of generated or processed audio.
Inception Methods#
The following methods apply if class labels are available for the training data of a generative model. They rely on a so-called Inception network – a classifier trained to predict the class labels from the data.
Inception Score (IS)#
The Inception Score is a metric that evaluates the quality and diversity of generated samples by measuring two key properties: (1) high confidence in classifications (suggesting realistic, distinct samples) and (2) diversity across classes (indicating a wide variety of generated outputs).
It uses a pre-trained Inception network to classify generated samples and calculates the score as follows:
In this formula:
\( p(y|x) \) represents the conditional class distribution given a generated sample \( x \), where higher confidence corresponds to more realistic samples.
\( p(y) \) is the marginal class distribution across samples, promoting diversity if samples cover a wide range of classes.
The Kullback-Leibler divergence \( D_{\text{KL}} \) between \( p(y|x) \) and \( p(y) \) is averaged over all generated samples, capturing the balance between realism and diversity. The exponential of this average yields the final Inception Score, with higher values indicating better quality.
IS is commonly applied in image generation but can be adapted for use in generative audio and other domains.
Kernel Inception Distance (KID)#
Kernel Inception Distance (KID) is a metric that evaluates the similarity between real and generated samples. Unlike IS, which only uses generated samples, KID compares the distributions of real and generated data using features extracted by a pre-trained Inception network. KID is calculated by computing the squared Maximum Mean Discrepancy (MMD) between the embeddings of real and generated samples, with a polynomial kernel for smoothing:
Here:
\(\phi(x_r)\) and \(\phi(x_g)\) represent the feature embeddings of real and generated samples, respectively.
MMD measures the difference in means of these embeddings, with KID summing the squared differences to capture distributional similarity.
Unlike FAD, which uses covariance matrices, KID operates without assumptions about distribution shape and generally provides unbiased estimates, especially in small sample sizes. Lower KID values suggest that generated samples closely match the distribution of real samples, making it suitable for generative tasks requiring high-quality and realistic outputs.
Subjective Evaluation#
Objective evaluation metrics cannot capture all the details people care about when listening to audio. Therefore, it is very common (and important) in audio generation works to perform user studies where human listeners assess the perceived quality of audio, focusing on aspects like naturalness, clarity, and overall fidelity. For completeness, we also include methods in this section that are used to compare the audio quality of two or more audio files, typically used in audio enhancement, super resolution or restoration.
For reliable results in all methods, it is crucial to conduct tests in controlled listening environments, ideally with high-quality audio equipment. Statistical analysis (like t-test) is often applied afterward to ensure the results are significant and unbiased.
Without Reference Samples#
The following metrics are used in cases where an absolute reference isn’t available, which typically applies to musical audio generation.
Single Stimulus Rating (SSR) allows listeners to rate each sample individually. This method is helpful when comparing samples of widely differing qualities, without needing a reference sample. One of the most widely used SSR methods is the Mean Opinion Score (MOS), where listeners rate each audio sample on a numerical scale, typically from 1 to 5 (i.e., Likert Scale), with higher scores indicating better quality. MOS is popular because it gives a straightforward average score for quality, often applied in areas like audio generation, speech synthesis and audio enhancement.
In order to obtain meaningful results for SSR in audio generation, samples from different datasets are presented to the user, for example real data and generated data.
Attribute-Specific Rating (ASR) asks listeners to rate audio on specific qualities, like brightness, clarity, or naturalness, giving a more nuanced evaluation across multiple dimensions. This approach is particularly useful when certain attributes are especially important, like naturalness in speech synthesis.
With Reference Samples#
In Comparison Category Rating (CCR), listeners are presented with two audio samples, often a high-quality reference and a processed version, and rate the difference in quality between them. This method helps detect subtle quality changes by making a direct comparison, which is useful for assessing codecs and noise reduction techniques.
For more precise distinctions, ABX Testing is a go-to approach. In this test, listeners hear three samples—two known (A and B) and one unknown (X) that matches either A or B. They must identify which one X corresponds to, revealing subtle perceptual differences. ABX tests are commonly used to test the transparency of audio processing techniques.
Another evaluation approach is the Degradation Category Rating (DCR), which involves rating the perceived degradation of an audio sample relative to a high-quality reference. Listeners rate how much the quality has deteriorated, ranging from “imperceptible” to “very annoying,” making DCR effective in testing the negative impacts of audio processing and compression methods.
In the MUSHRA (MUltiple Stimuli with Hidden Reference and Anchor) test, listeners rate multiple versions of the same audio on a scale from 0 to 100, with both high-quality and low-quality references included. MUSHRA provides detailed insight across various conditions, making it useful for codec testing and audio enhancement evaluations.