
Introduction#
Organisation of the book#
The first part of the book, “Tasks”, describes a subset of typical audio-based MIR tasks.
To facilitate the reading of the book, we follow a similar structure to describe each of the audio-based MIR tasks we consider.
We describe in turn:
the goal of the task
the performance measures used to evaluate the task
the popular datasets used for the task
(Datasets can be used to train system or evaluate the performances of a system.)how we can solve the task using deep learning.
(This part refers to bricks that are described individually in the second part of the book.)
The second part of the book, “Deep Learning Bricks”, describes each brick individually.
We have chosen to separate the description of the bricks from the tasks in which they can be used in order to emphasise the fact that the same brick can be used for several tasks.

Fig. 1 Overall description of tasks in terms of goal/evaluation/datasets/model#
Simplifying the development#
To make our life easier and facilitate the reading of the code of the notebooks we will rely on the following elements.
for datasets (audio and annotations): .hdf5 (for audio) and .pyjama (for annotations), described below
for deep learning: pytorch (a python library for deep learning)
for the dataset/dataloader
for the models, the losses, the optimizers
for training: pytorch-lightning (a library added to pytorch that makes it easier/faster to train and deploy models)
Evaluation metrics#
In the notebooks, we will rely most of the time on
mir_evalwhich provides most MIR specific evaluation metrics,scikit-learnwhich provides the standard machine-learning evaluation metrics.
In summary#
We summarize the various elements of code to be written below.
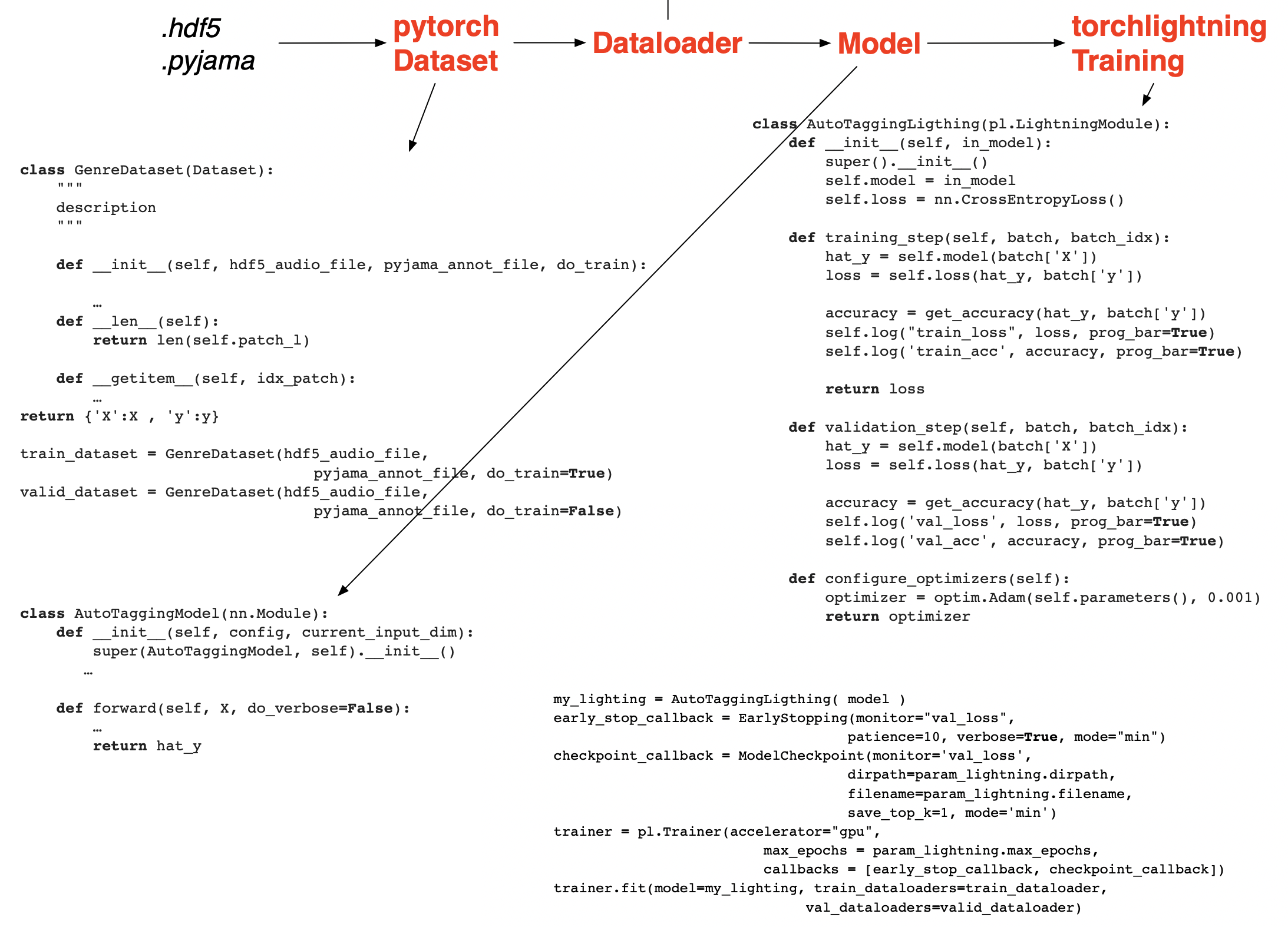
Fig. 2 Code to be written#