
Pytorch#
dataset/dataloader#
To help understanding what a dataloader should provide, we use a top-down approach.
We start from the central part of the training of a deep-learning model.
It consists in a loop over epochs and for each an iteration over batches of data:
for n_epoch in range(epochs):
for batch in train_dataloader:
hat_y = my_model(batch['X'])
loss = my_loss(hat_y, batch['y'])
loss.backward()
...
In this, train_dataloader is an instance of the pytorch-class Dataloader which goal is to encapsulate a set of batch_size paris of input X/output y which are each provided by train_dataset.
train_dataloader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size = batch_size,
shuffle = True)
train_dataset is the one responsible for providing the X and the y.
It is an instance of a class written by the user (which inherits from the pytorch-class Dataset).
Writing this class is probably the most complex part.
It involves
defining what should the
__getitem__return (theXandyfor the model) andprovides in the
__init__all the necessary information so that__getitem__can do its job.
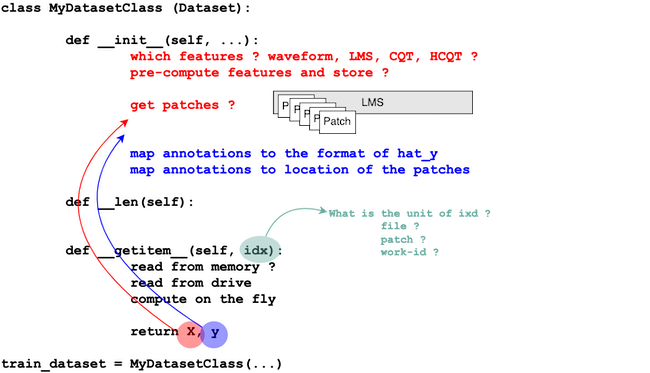
Fig. 3 Writting a Dataset class#
It involves defining
X
what is the input representation of the model ? (
Xcan be waveform, Log-Mel-Spectrogram, Harmonic-CQT),where to compute it
compute those one-the-fly in the
__getitem__?pre-compute those in the
__init__and read them on-the-fly from drive/memory in the__getitem__?
In the first notebooks, we define a set of features in the feature.py package (feature.f_get_waveform, feature.f_get_lms, feature.f_get_hcqt).
We also define the output of __getitem__/X as a patch (a segment/achunk) of a specific time duration.
The patches are extracted from the features which are represented as a tensor (Channel, Dimension/Frequency, Time).
In the case of waveform the tensor is (1,Time), of LMS it is (1,128,Time), of H-CQT it is (6,92,Time).
To define the patch, we do a frame analysis (with a specific window lenght and hope size) over the tensor.
We pre-compute the list of all possible patches for a given audio in the feature.f_get_patches.
It involves mapping the annotations contained in the .pyjama file (such as pitch, genre or work-id annotations)
to the format of the output of the pytorch-model,
hat_y, (scalar, matrix or one-hot-encoding) andto the time position and extent of the patches
X.
It involves defining what is the unit of
idxin the__getitem__(idx).
For example it can refer toa patch number,
a file number (in this case
Xrepresents all the patches a given file) ora work-id (in this case
Xprovides the features of all the files with the same work-id).
Below is an example of such a dataset code.
We first get all the information ready.
class TagDataset(Dataset):
def __init__(self, hdf5_audio_file, pyjama_annot_file, do_train):
with open(pyjama_annot_file, encoding = "utf-8") as json_fid: data_d = json.load(json_fid)
entry_l = data_d['collection']['entry']
# --- get the dictionary of all labels (before splitting into train/valid)
self.labelname_dict_l = f_get_labelname_dict(data_d, config.dataset.annot_key)
self.do_train = do_train
# --- The split can be improved by filtering different artist, albums, ...
if self.do_train: entry_l = [entry_l[idx] for idx in range(len(entry_l)) if (idx % 5) != 0]
else: entry_l = [entry_l[idx] for idx in range(len(entry_l)) if (idx % 5) == 0]
self.audio_file_l = [entry['filepath'][0]['value'] for entry in entry_l]
self.data_d, self.patch_l = {}, []
with h5py.File(hdf5_audio_file, 'r') as audio_fid:
for idx_entry, entry in enumerate(tqdm(entry_l)):
audio_file= entry['filepath'][0]['value']
audio_v, sr_hz = audio_fid[audio_file][:], audio_fid[audio_file].attrs['sr_hz']
# --- get features
if config.feature.type == 'waveform': feat_value_m, time_sec_v = feature.f_get_waveform(audio_v, sr_hz)
elif config.feature.type == 'lms': feat_value_m, time_sec_v = feature.f_get_lms(audio_v, sr_hz, config.feature)
elif config.feature.type == 'hcqt': feat_value_m, time_sec_v, frequency_hz_v = feature.f_get_hcqt(audio_v, sr_hz, config.feature)
# --- map annotations
idx_label = f_get_groundtruth_item(entry, config.dataset.annot_key, self.labelname_dict_l, config.dataset.problem, time_sec_v)
# --- store for later use
self.data_d[audio_file] = {'X': torch.tensor(feat_value_m).float(), 'y': torch.tensor(idx_label)}
# --- create list of patches and associate information
localpatch_l = feature.f_get_patches(feat_value_m.shape[-1], config.feature.patch_L_frame, config.feature.patch_STEP_frame)
for localpatch in localpatch_l:
self.patch_l.append({'audiofile': audio_file, 'start_frame': localpatch['start_frame'], 'end_frame': localpatch['end_frame'],})
def __len__(self):
return len(self.patch_l)
We then pick up the information corresponding to an idx, here the unit is a patch.
def __getitem__(self, idx_patch):
audiofile = self.patch_l[idx_patch]['audiofile']
s = self.patch_l[idx_patch]['start_frame']
e = self.patch_l[idx_patch]['end_frame']
if config.feature.type == 'waveform':
# --- X is (C, nb_time)
X = self.data_d[ audiofile ]['X'][:,s:e]
elif config.feature.type in ['lms', 'hcqt']:
# --- X is (C, nb_dim, nb_time)
X = self.data_d[ audiofile ]['X'][:,:,s:e]
if config.dataset.problem in ['multiclass', 'multilabel']:
# --- We suppose the same annotation for the whole file
y = self.data_d[ audiofile ]['y']
else:
# --- We take the corresponding segment of the annotation
y = self.data_d[ audiofile ]['y'][s:e]
return {'X':X , 'y':y}
train_dataset = TagDataset(hdf5_audio_file, pyjama_annot_file, do_train=True)
valid_dataset = TagDataset(hdf5_audio_file, pyjama_annot_file, do_train=False)
models#
Models in pytorch are usually written as classes which inherits from the pytorch-class nn.Module.
Such a class should have
a
__init__method defining the parameters (layers) to be trained anda
__forward__method describing how to do the forward with the layers defined in__init__
(for example how to go fromXtohat_y).
class NetModel(nn.Module):
def __init__(self, config, current_input_dim):
super().__init__()
self.layer_l = []
self.layer_l.append(nn.Sequential(...))
...
self.model = nn.ModuleList(self.layer_l)
def forward(self, X, do_verbose=False):
hat_y = self.model(X)
return hat_y
In practice, it is common to specify the hyper-parameters of the model (such as number of layers, feature-maps, activations) in a dedicated .yaml.
In the first notebooks, we go one step further and specify the entire model in a .yaml file.
The code then becomes much more readable.
The class
model_factory.NetModelallows to dynamically create model classes by parsing this file
Below is an example of such a .yaml file.
model:
name: UNet
block_l:
- sequential_l: # --- encoder
- layer_l:
- [BatchNorm2d, {'num_features': -1}]
- [Conv2d, {'in_channels': -1, 'out_channels': 64, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]
- [Conv2d, {'in_channels': -1, 'out_channels': 64, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]
- [Activation, ReLU]
- layer_l:
- [StoreAs, E64]
- layer_l:
- [BatchNorm2d, {'num_features': -1}]
- [Conv2d, {'in_channels': -1, 'out_channels': 128, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]
- [Conv2d, {'in_channels': -1, 'out_channels': 128, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]
- [MaxPool2d, {'kernel_size': [2,2]}]
- [Activation, ReLU]
- layer_l:
- [StoreAs, E128]
- layer_l:
- [BatchNorm2d, {'num_features': -1}]
- [Conv2d, {'in_channels': -1, 'out_channels': 256, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]
- [Conv2d, {'in_channels': -1, 'out_channels': 256, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]
- [MaxPool2d, {'kernel_size': [2,2]}]
- [Activation, ReLU]
- layer_l:
- [StoreAs, E256]
- layer_l:
- [BatchNorm2d, {'num_features': -1}]
- [Conv2d, {'in_channels': -1, 'out_channels': 512, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]
- [Conv2d, {'in_channels': -1, 'out_channels': 512, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]
- [MaxPool2d, {'kernel_size': [2,2]}]
- [Activation, ReLU]
- sequential_l: # --- decoder
- layer_l:
- [BatchNorm2d, {'num_features': -1}]
- [ConvTranspose2d, {'in_channels': -1, 'out_channels': 256, 'kernel_size': [2,2], 'stride': [2,2]}]
- [Conv2d, {'in_channels': -1, 'out_channels': 256, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]
- [Conv2d, {'in_channels': -1, 'out_channels': 256, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]
- [Activation, ReLU]
- layer_l:
- [CatWith, E256]
- layer_l:
- [DoubleChannel, empty]
- [BatchNorm2d, {'num_features': -1}]
- [ConvTranspose2d, {'in_channels': -1, 'out_channels': 128, 'kernel_size': [2,2], 'stride': [2,2]}]
- [Conv2d, {'in_channels': -1, 'out_channels': 128, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]
- [Conv2d, {'in_channels': -1, 'out_channels': 128, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]
- [Activation, ReLU]
- layer_l:
- [CatWith, E128]
- layer_l:
- [DoubleChannel, empty]
- [BatchNorm2d, {'num_features': -1}]
- [ConvTranspose2d, {'in_channels': -1, 'out_channels': 64, 'kernel_size': [2,2], 'stride': [2,2]}]
- [Conv2d, {'in_channels': -1, 'out_channels': 64, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]
- [Conv2d, {'in_channels': -1, 'out_channels': 64, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]
- [Activation, ReLU]
- layer_l:
- [CatWith, E64]
- layer_l:
- [DoubleChannel, empty]
- [BatchNorm2d, {'num_features': -1}]
- [Conv2d, {'in_channels': -1, 'out_channels': 1, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]
- [Conv2d, {'in_channels': -1, 'out_channels': 1, 'kernel_size': [3,3], 'stride': 1, 'padding': 'same'}]